




【导读】深度学习为何这几年火爆?机器有可能具备意识吗?如何加强这方面的培训?大量人工智能的运行所产生的碳排放有无可能降到最低?青年研究员为何选择与他人互动比死守自己成果要更好?7月9日至11日,世界人工智能大会成功落幕后,每年一度的中国人工智能大会(Chinese Congress on Artificial Intelligence 2020,简称“CCAI 2020”)将于8月29日至30日在南京召开,本次主题是“智周万物”。蒙特利尔大学计算机科学与运筹学系教授、蒙特利尔学习算法研究所(Mila)的负责人、2018年ACM图灵奖获得者Yoshua Bengio将出席大会并做主题发言。他是深度学习的创始人之一,业界公认的该领域先驱。今分享其此前接受MIT助理教授韩松的访谈录。
1985年开始耕耘神经网络研究,对假设的激情支撑着20余年的冷板凳
韩松:您已经从事深度学习领域研究数十年了,能否与我们分享您的学术经历和目标,以及这个领域的发展状况?
Yoshua Bengio:科学家、研究人员和思想之间的关系是非常令人激动的。因此,我一直对自己的研究充满热情。说实话,在许多年前,我就爱上了一种“惊人的假设”:我们的智慧可以被几条简单的原理解释清楚。所以1985年左右,我开始阅读神经网络相关的论文。
Geoffrey Hinton的团队发表的论文给我的印象最为深刻。我当时就感觉,这就是我想要做的,这种感觉从那时开始就一直持续着。当我在1980年代末开始研究这个领域时,几乎没有人同时在做这件事。但是这个领域在当时很热门,很多人都准备加入研究行列。我在1991年取得了博士学位。但是在1990年代,随着其他机器学习方法的风靡,人们对神经网络的兴趣逐渐下降。因此,很长一段时间以来,正是这种激情让我致力于这一领域的研究。

中国人工智能大会将于8月29日至30日在南京召开,2018年ACM图灵奖获得者Yoshua Bengio将出席大会并做主题发言
深度学习带来了爆炸式增长,科学家要对这种全社会的改变负有责任
我曾试图理解神经网络以及内核方法等其他方法的局限性,这种尝试使我从数学的角度上更深入地验证了我的直觉的正确性。当然,在过去的十年中,成功的应用程序和基准测试,甚至是整个机器学习领域都发生了爆炸式增长。这是要归功于深度学习的,深度学习不仅是大学中的一门学科,而已经在整个社会中都有所应用,这其中也蕴含着巨大的商机。深度学习正在改变着我们的社会,然而这些转变并不都是有益的,因此我们要时刻怀着一份责任感。
科学家处在意识研究的“全局工作空间”阶段,该功能为人类提供进化优势
韩松:您发表的精彩演讲中,我认为意识/注意力模型是其中的核心部分。您能否分享更多的关于这方面的想法和成果呢?
Yoshua Bengio:是的,这十分有趣。“意识”一词长久以来在科学界都是一个禁忌。但是在最近的几十年中,神经科学家和认知科学家已经开始探讨意识的真正内涵。当然,它有不同的方面。科学家们提出了几种有趣的理论,例如全局工作空间理论。我认为我们目前正处于这种阶段:机器学习(尤其是深度学习)已经可以开始研究神经网络架构以及实现其中某些功能的目标功能和框架。对个人而言,最令我感到兴奋的是这些功能可能为人类提供进化优势。因此,如果我们了解这些功能,它们也将对AI有所帮助。
注意力机制对应的假设:如何构建对世界的认识,涉及知识表示和语言
韩松:说到意识与注意力之间的关系,我们可不可以认为注意力其实就是正在寻找从无意识集合的大维度到低维度意识集合的映射,并以此帮助泛化?
Yoshua Bengio:正是这样。有趣的是,每次只需要选择几个变量就可以了,根据我的理论,我们需要的是一个正则项和一个对环境的先验条件。人们会利用这个先验条件来构建高级的概念,并用语言来表达它。比如,我说这样一句话:“如果我把球抛出去,它会落在地上。”这句话只涉及了几个概念,而注意力会选择恰当的词和几个概念,它们彼此间是有很强的依赖性的。所以,我就可以通过它们来预测某些动作的效果,而这句话表达的就是这个含义。而且,该事件的发生概率很高。从某种意义上说,这是十分杰出的。我们能够使用很少的信息和变量去预测未来,这一点是十分非同寻常的。
因此,这种注意力机制对应了一种假设:我们应该如何去构建对世界的认识。它涉及了知识表示和语言,我们使用语言来处理的概念可以与我们在脑海中具有最高表示能力的概念相对应。

7月9日至11日,2020世界人工智能大会成功举办
递归独立机制(RIM)发现,可将知识组成动态组合小片段来适应改变
韩松:因此,这不仅是语言而且是强化学习,正如您在最近发表的RIM(递归独立机制)论文中所展示的那样,与传统RNN相比,雅达利游戏展现出了强大的泛化能力。
Yoshua Bengio:是的,所以说到意识,我认为对于学习而言,机器对于学习主体尤其重要。学习主体是在环境中活动的实体,诸如人类、动物以及未来可能会制造的机器和机器人等。但是主体们会面对一个问题,那就是周围的世界正在发生变化。因此,他们需要能够适应并且快速了解这些改变。对此,我提出了意识机制,通过将他们的知识组织成可以像RIM论文中那样动态重新组合的小片段,来帮助他们做到适应改变。面对环境中的变化时,我们也可以更加从容。而且我们确实在实验中发现,与训练期间所见的相比,这些类型的体系结构可以更好地推广到,比如说,更长的序列。
韩松:因此,我们不再需要重新整理数据,而仅需要关注它应该处理的数据来使其泛化?
Yoshua Bengio:是的,我们不想重新整理数据。因为当我们对数据进行重新整理时,会破坏部分信息,对吧?在我们重新整理后,整体结构都会发生改变。然而这种结构可能从信息刚被收集时就存在了。要知道,某些因素的改变会导致数据发生些许变化。当我们整理数据时,这部分信息就丢失了。当然,这么做使泛化变得更加容易,但这其实算是一种作弊,因为在现实世界中,数据不会被重新整理。明天将要发生的事情与昨天发生的事情将不会完全一样。因此,我们要做的不是重新整理,而是构建一个对这些改变具有鲁棒性的系统。这也是元学习发挥作用的时候。
类似物种通过进化来优化日常行为,如何优化学习者的学习方式是研究重点
韩松:是的,说到元学习,您在1990年代就发表过一篇关于元学习和学会学习的论文,这篇文章最近随着神经体系结构搜索的发展又变得非常热门。您能否分享一些您对于“学会学习”的思考和进展?
Yoshua Bengio:好的。当我开始考虑“学会学习”时,人们还没有将其称为元学习,就只是在学习要如何去学习。我当时受到了个体或动物的学习与进化之间关系的启发。这种说法并不准确,但是您可以认为进化有点像是优化,因为物种通过进化来优化他们的日常行为。然后,我们的外部循环就像一个缓慢的时间轴,随着这个过程的不断发展,越来越好的解决方案被提出。但是在个体的一生中,学习也会带来很多进步。因此,这个过程就像在学习中学习。正如我们在论文中所展示的那样,您可以使用与我们刚刚使用的反向传播相同的工具来同时优化这两件事。我们最近主要专注于,如何运用这些思想来优化学习者的学习方式,不仅可以使他们在特定任务上完成得更出色,而是更好地去学会学习。
因此,一旦掌握了泛化能力,即使外部环境发生了变化也可以更好地去适应,也就是说对于改变的鲁棒性提高了。如果您在普通静态框架下只假设一种条件分布来进行普通训练,那么这种鲁棒性是不可能实现的。但是理论上,元学习可以进行端到端的学习,学习如何泛化变更和分布并且获得鲁棒性。所以从概念上讲,这一点的意义十分重大。
韩松:我完全同意。但是由于我们嵌套了两层循环,因此计算复杂度变得相当高。
Yoshua Bengio:这就是为什么多年来这个领域都不算太热门。但是现在,我们比1990年代初期拥有更多的计算能力。我们开始发现元学习的强大之处,比如通过很少的示例就能完成学习等等。这些都要归功于GPU和TPU的额外计算能力。
DeepMind 构建了一个名为 Agent57 的智能体,该智能体在街机学习环境包含所有 57 个雅达利游戏,实现了超越人类的表现
某些神经结构运行碳足迹要大于五辆汽车能耗,目前正从算法和硬件着手降低
韩松:我还注意到这种训练留下的碳足迹可以说非常之多。您专门创建了一个计算二氧化碳排放量和成本的网站。您的初衷是什么?是关于环保方面的思考吗?Yoshua Bengio:对。生活中什么事情都不简单,许多细节都很重要。其实,机器学习可以用来应对气候变化。我们发表了一篇很长的论文,解释了机器学习在气象科学和材料科学中的许多应用,例如帮助提高电能和可再生能源的使用效率。因此,我们可以使用机器学习来帮助人类解决气候变化这一重大挑战。但与此同时,所有这些计算能力都依赖于不可再生能源,并因此产生了巨量的碳足迹。这其实取决于您在哪里进行实验。比如说,我居住在魁北克省,那里使用的就是100%可再生的水力发电,所以并不会产生碳足迹;但是如果您在美国,或者是在有着大量煤炭资源的中国,就是另一回事了。大型实验会消耗大量的能源。更令人担忧的是,工业界的研究人员正在逐步建立越来越大的模型。这些模型的增长速度非常快,大概每三个月就会翻一番。
韩松:比摩尔定律更快。
Yoshua Bengio:对,就是这样,比摩尔定律还要快。您要知道,我们是无法维持这种扩张的,为了运行这么多大型的AI系统,我们最终甚至会用光所有电能。这可不太妙。因此,我们需要像您这样的研究者来帮助我们设计能够更高效地利用能源的系统。所以,您认为我们应该如何解决这个问题?
韩松:我认为我们需要从算法和硬件两方面来解决如此具有挑战性的难题。按照惯例,我们过于依赖摩尔定律,期望者计算机的运行速度每年都会更快。然而随着摩尔定律的放慢,我们需要研究算法和硬件这两部分,以减少内存占用,而且我认为正是内存占用导致了能耗。运算成本并不高,但是存储成本很高。我们已经取得了一些进展,比如在深度压缩(Deep Compression)可以将模型大小减小一个数量级,进而减少内存。高效推理引擎(Efficient Inference Engine)通过跳过零(零与零的乘积为零)来保存计算。最近,我们一直在致力于降低Transformers的神经网络架构研究的开销,在之前,它的碳足迹比得上五辆汽车在寿命周期内排放的碳总量。
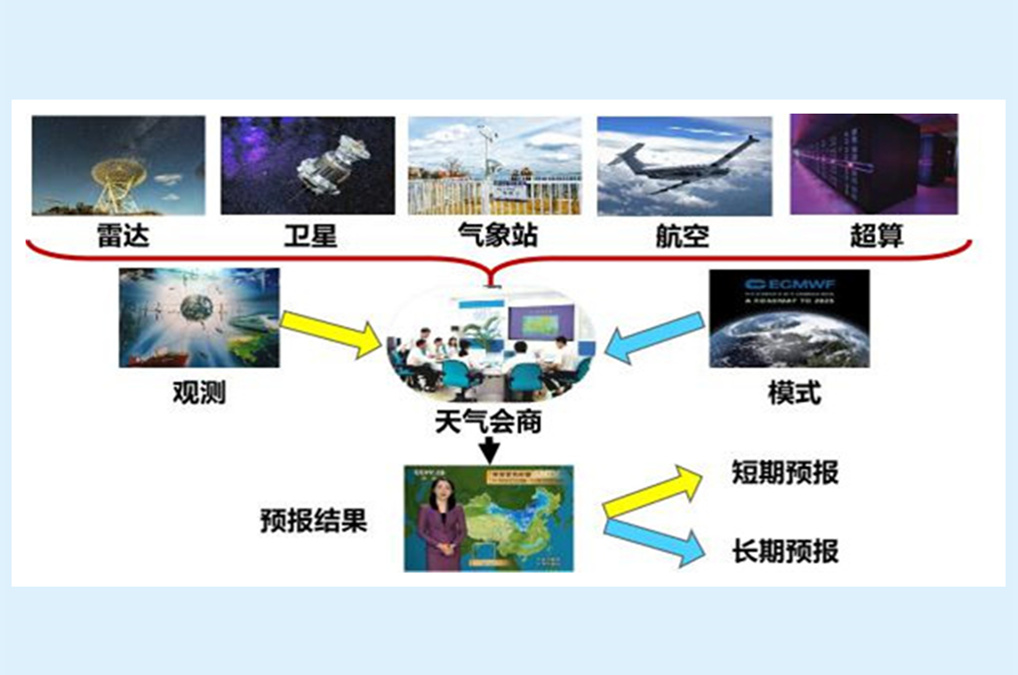
机器学习在天气会商智能化中的应用
人类智能结合机器智能,对搜索空间进行剪枝,使之更具成本效益
Yoshua Bengio:这就是另一个细节问题了,媒体报道的那些天文数字主要来源于在架构和超参数空间中进行的超参数优化搜索。它们的成本比训练单个网络要贵上1000倍。因此,如果您像我一样在学术界,计算能力有限,您需要依靠人脑来进行搜索,这种方式的能耗要低得多。您的计算资源可能有限,但是您手下有许多正在做实验的学生们,他们过去曾经做过许多实验,他们知道要如何去研究,所以能够找到不错的解决方案。然而我们目前用于探索架构空间的方法更像是暴力破解,成本非常高。
韩松:是的,完全同意。我去年刚加入麻省理工学院时,只有八块GPU卡,而我的学生们不可能用它们来进行神经结构搜索。因此,他必须以将人类智能与机器智能结合起来,对搜索空间进行剪枝。最后,我们以更具成本效益的方式完成了搜索。
Yoshua Bengio:那很棒。
不要急于在各个截止日期之间奔波,与他人互动中调动生产力
韩松:谢谢。您作为AI研究领域的领军人物,您对青年研究者未来的发展方向有何建议?
Yoshua Bengio:当前的机器学习和AI领域的学生和研究人员的竞争非常激烈,压力非常大,他们大多都感到非常焦虑,我对此感到十分沮丧。因为科学研究并不应该在这些条件下进行,而是应该制定长远的目标,留出足够的时间仔细推敲、集思广益,并勇于将各种想法付诸实践。但现状与之相反,当下,我们急于在各个截止日期之间奔波,每隔两个三个月,我们就有另一个截止日期。我认为这对这个领域十分不利。而且这对研究者的心理健康也不是很好,人不能总处于这么大的压力之中。
所以我的建议是往后退一步,去设定一些更充满野心的目标,去解决一些更棘手的问题,而不是一直去想在接下来的几周内,或者在下一个截止日期之前应该做什么。多听听内心的直觉。然后,您需要去分享您的想法,和别人多多谈论它们。即使这些想法尚未发布,也不要害怕其他人会窃取您的想法。比起死死守住自己的成果,与他人积极互动不仅会在心理上对您产生积极的影响,还能够调动生产力。
编辑:袁琭璐
责任编辑:李念
综合《中国人工智能学会》《北青网》