




AI要学会国际象棋,是不是一定要下过棋才行?
不一定。
伦敦大学学院的小伙伴们,开发了一只新的国际象棋AI,只看人类对比赛的评论,就能学会下棋。
AI的名字叫SentiMATE,是通过解说员/评论员言语里的情绪,来判断一手棋的好坏。
团队发现,只靠这些情绪,AI就学到了国际象棋的基本规则,以及一些关键策略,并战胜了前辈DeepChess算法。
重点是,它对训练数据量的要求还不高。
那么,这只AI到底都经历了什么?
不一样的学习方法
故事要从大部分国际象棋AI的工作方式讲起。
现在的国际象棋算法,基本都有两个关键部分:
一是搜索算法,用来搜索所有可能的下一步,搭起一棵树,树上有很多节点。
二是评估算法,用来分析如果走到树上的某个节点,会有怎样的优势。
比如,这就是一棵树,
而SentiMATE,就是把第二部分,换了一种方法来做:
分析比赛评论里句子的情绪,判断每手棋的好坏,由此训练一个新的评估函数。
情绪评估
评论的文本,是从一个国际象棋论坛上扒的。
为了分析评论员的情绪,团队用到了两个分类器。
第一个分类器,要从解说文本里,把形容一手棋质量的评论挑出来,无关质量的扔出去。
研究人员用手动标注的2700条评论,再加上另外300条作为测试集,训练好了这个二分类器。
这样从能就原始数据集里,筛选出有用的评价了。
第二个分类器,要从筛选好的句子里,分析出情绪。

这个部分很关键,也很复杂。因为有些句子,很难判断情绪是正面还是负面:
比如,“保护了这枚棋子 (Protecting a Piece) ”,可以看作一步棋避免了负面的后果,也可能说明当前的状态比较危险。
再比如,“攻击 (Attack) ”这个词对普通的情绪分析AI来说是贬义,容易被分类成负面情绪。可“对后的攻击 (an Attack on the Queen) ”,通常是步有利的棋。
这样,上下文对情绪的理解就很重要了。而数据集里的样本,多是短文本,没有太多上下文可以参考。
团队选择了Flair用的架构。Flair是Zalando Research开发的一个NLP库。
研究人员认为,在文本很短的情况下,LSTM (长短期记忆) 加上合适的词嵌入方法,会有助于学到国际象棋背景下的用词规律。
于是,在word2vec词嵌入的基础上,又加了一些上下文的字符串嵌入 (Contextual String Embeddings) ,用来提升分类的准确度。
这样,有利于在一个小训练集 (团队只标注了2090条评价的感情,分正面和负面) 上,给一些情绪模糊的文本做分类。
情绪分类做好之后,就到最重要的一步了:
每步棋的质量评估
团队用的评估方式,和从前的AI很不一样。
前人用的数据多是静止的棋盘状态,没有关于每步棋的信息。训练过程相对低效,需要巨大的数据量,才能比较好地泛化。
而这里,是把落子之前和之后的棋盘 (下图左) ,一起输入神经网络,搭配刚分析出的情绪 (下图右) 。如此,补全了从前被遗忘的数据,训练会更高效。
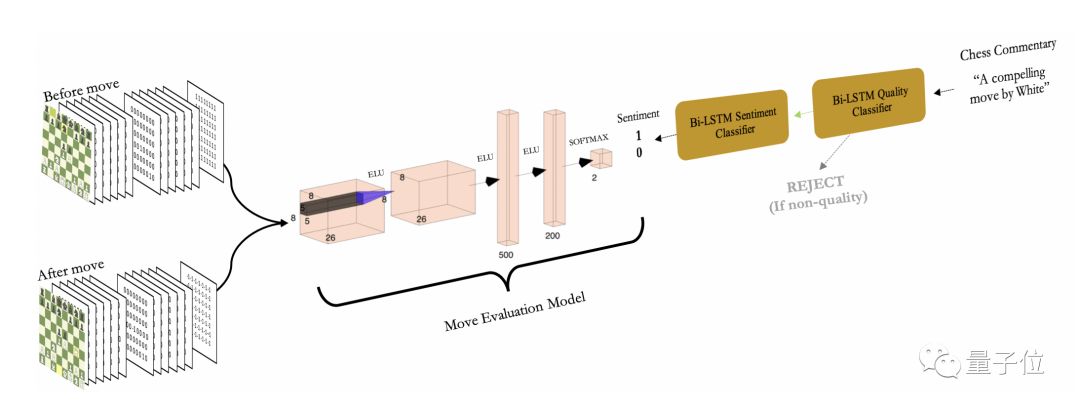
中间部分,是质量评估网络(质量评估网络的架构,是团队基于Sabatelli等人2017年提出的方法搭的。)
团队说,像下围棋的AlphaZero,要经过百万/千万次迭代 (Iterations) 的自我对弈,用上几千个GPU,才能出师;
而学界通常没有这样的条件,所以提升评估算法的效率非常重要。
那么,成果怎么样呢?
赢了DeepChess
首先,看一下两个分类器的效果。
第一个分类器,找到能描述一步棋质量如何的评论:
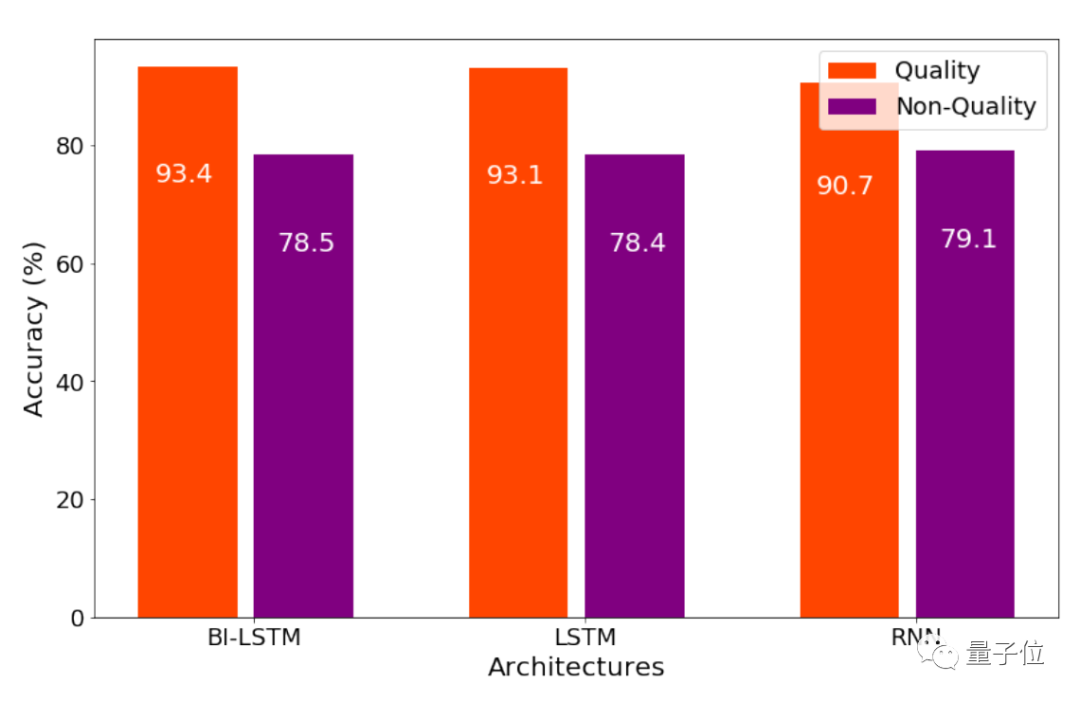
团队尝试了三种网络,发现双向LSTM表现最好,识别有用评论的准确率是93.4%,超越了普通LSTM和普通RNN。
然后,又在表现最好的双向LSTM上面,尝试了不同的词嵌入方法:
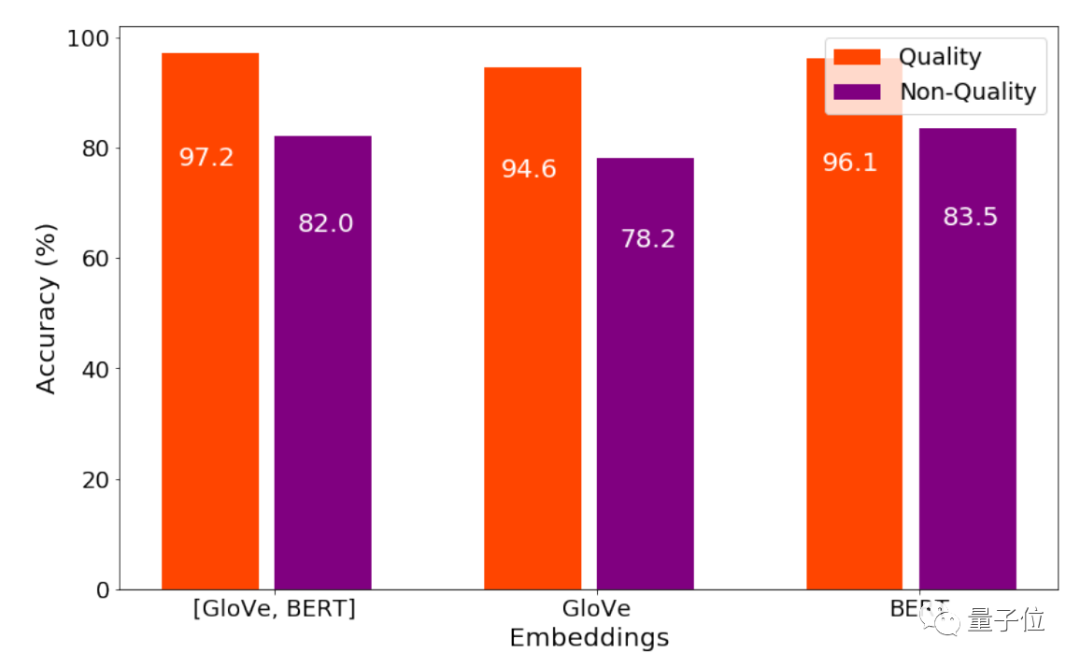
发现把BERT和GloVe的嵌入结合起来,是表现最好的,识别有用评论的准确率达到了97.2%。
第一步颇有成效,下面是第二个分类器,评估情绪的正面负面:
这是一个LSTM分类器,用2090条评论来训练,用233条评论来测试的。
结果是,识别正面情绪的准确率是91.42%,平衡准确率 (Balanced Accuracy) 是90.83%。
超越了CNN-RNN架构,超越了双向LSTM。
顺便说句,这个分类器里表现最好的词嵌入方式来自BERT。
到这里,第二步也得到了有效的成绩。
那么,SentiMATE最终有没有学会下棋?还是要真刀真枪比赛才行:
首先,和随机AI对战100场,胜率81%。
然后,和2017年诞生的DeepChess (的一个实现) 对战。
由于计算的限制 (Computational Constraints) ,SentiMATE没办法向前查看 (Look-Ahead) 很多步,来评估一手棋的好坏,所以把自己和对手搜索深度设为1,就是只向前查看一步。
在这个条件下,SentiMATE执黑和执白都战胜了对手。

MIT科技评论报道说,AI掌握了许多关键策略,比如捉双 (Forking) 和异位 (Castling) 等等。
研究人员还注意到,这只AI很喜欢王兵开局 (King Pawn opening) ,这是一种十分激进、带有攻击性的操作,能迅速打开局面。
国际象棋特级大师鲍比·费舍尔 (Bobby Fischer) 也说过:实践证明,这是最好的开局方式。
虽然,SentiMATE现在只能往前推算一步,但依然证明了NLP可以训练出有效的评估函数,并且用少量样本就能达成。
这样,就为今后的棋类AI训练,提供了一个清新低碳的思路,意义不小。

编辑:朱颖婕
责任编辑:顾军
来源:综合自量子位、领研等
违法与不良信息举报电话:021-22898778
本网站文字、图片和视频作品,除特别说明外均为独家授权发布,转载请注明出处和原文链接。